Building Git Pull Requests with Jenkins
by Sebastien Mirolo on Wed, 15 Apr 2020
 Through the years and Jenkins releases, we build Jenkins jobs that are able
to run tests on the master branch.
With more and more casual contributors, we want to be able to run tests
on Pull Requests, automatically adding annotations for the test
results.
Through the years and Jenkins releases, we build Jenkins jobs that are able
to run tests on the master branch.
With more and more casual contributors, we want to be able to run tests
on Pull Requests, automatically adding annotations for the test
results.
Getting Started
As a first step, we want to discover pull requests, create jobs for them, and remove jobs when those branches dissapear, automatically.
The top results on Google recommend GitHub Pull Request Builder to integrate GitHub pull requests with Jenkins. When you look at GitHub Pull Request Builder page, the plug-in hasn't been updated in 2 years and is up for adoption.
So we will start with GitHub Branch Source which provide the required functionality.
GitHub Branch Source has the ability to scan a GitHub Organization for all its repositories through a Jenkins GitHub Organization project. A GitHub Organization project is not required to use the PR jobs feature though. Once the plugin is installed, a regular Multibranch Pipeline will also have the desired functionality.
We are currently running a multi-configuration project with the following steps:
- Build webserver image
- Deploy webserver
- Run tests against webserver
- Teardown webserver
- Publish code coverage report
- Publish test result report
- Publish static code analysis report
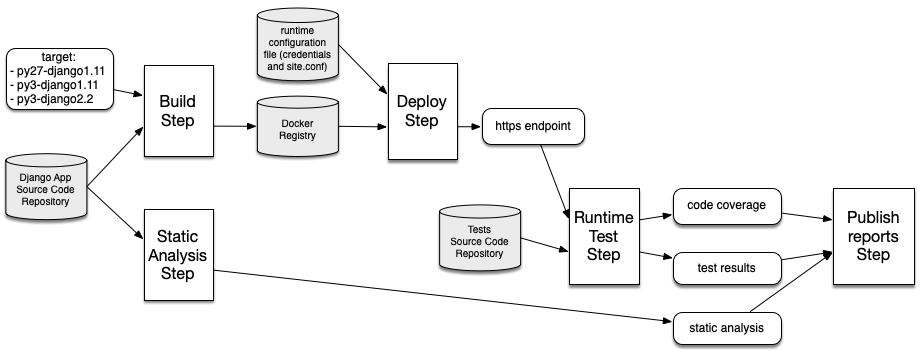
To use the multibranch projects feature required by GitHub Branch Source, we need to convert the current multi-configuration project into a pipeline.
Figuring out what a pipeline script (Jenkinsfile) should look like is a bit. of. trial. and. error. Fortunately after a while you figure out that there is Jenkins DSL (kind of deprecated) and Jenkins pipeline syntax (called workflows for a short while).
First tip: The Jenkins Pipeline Reference is a good place to find current relevant information at this point. Second tip: After you create a multibranch pipeline project, you can click on Pipeline Syntax, then pick a sample under Snippet Generator.
Overall considerations
Most of Jenkins documentation and tutorials start with a Jenkinsfile committed to "the" source repository. When you have a multi-repo setup and expect to let many random contributors generate pull requests, it is never an option.
After installing Pipeline: Multibranch with defaults, you will see an option to use a Jenkinsfile inside Jenkins itself instead of a Jenkinsfile committed to the repository. This requires to create a "Multibranch Pipeline" (not a "Multibranch Pipeline with defaults" as you could expect) and add a "Groovy file" under Manage Jenkins > Managed files > Add a new Config.

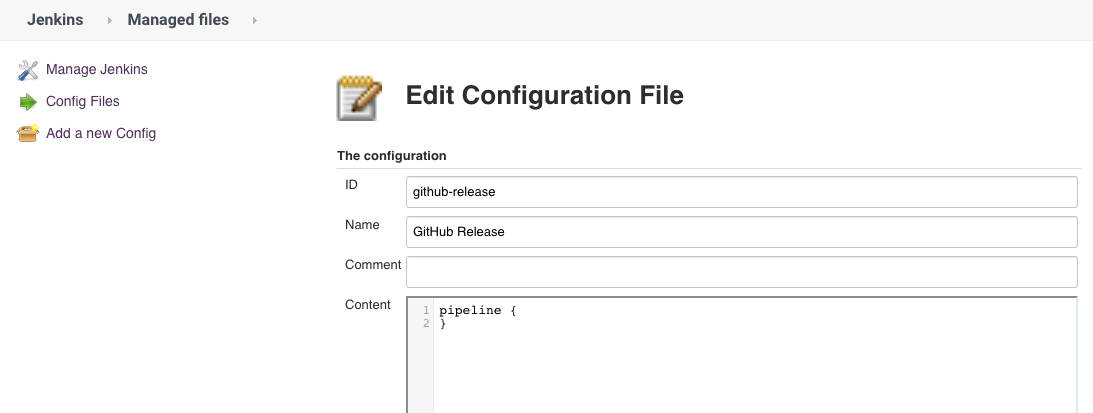
You will then have to Turn on sandbox mode (under Build Configuration in the Job configuration) or Go to Manage Jenkins > In-process Script Approval and click Approve unless you want to run into UnapprovedUsageException on the first run.
Running with default Jenkinsfile ID: Jenkinsfile org.jenkinsci.plugins.scriptsecurity.scripts.UnapprovedUsageException: script not yet approved for use
Since DjaoDjin projects are Open Source, we didn't create a specific GitHub account for Jenkins at first. We simply leaved the credentials fields empty. This lead to surprising permissions errors as well as severe quota restrictions.
Error while processing pull request
Reason: org.kohsuke.github.GHFileNotFoundException: https://api.github.com/repos/djaodjin/djaoapp/collaborators/username/permission {"message":"Requires authentication","documentation_url":"https://developer.github.com/v3/repos/collaborators/#review-a-users-permission-level"}
In the end since we want to comment on PRs with the status of test results, we created a GitHub account dedicated for the build bot.
GitHub disabled username/password credentials. So we need to create a personal access token for the buildbot. We enable permissions for repo:status, repo_deployment, public_repo.
After the scan completed, we have the 2 branches showing up but none of the Pull Requests. It turns out the error comes from the Trust settings we have to Discover pull requests from forks.
We want to give feedback to anyone creating a Pull Request on DjaoDjin's Open Source repository. At the same time, we want to make sure bad actors do not use the opportunity to insert malicious code. Thus the PR code shoud only be run in a sandbox, ideally after a code review. The problem here is all builds are triggered after the repository scan completes.
We install the Pipeline: Multibranch build strategy extension plugin, which amongst other things, can prevent build trigger when certain files change (ex: README).
Explicit checkout steps
The build process is taylored for a multi-repo setup. We thus want to skip the "Declarative: Checkout SCM" step and do a checkout step into a subdirectory of WORKSPACE.
pipeline {
agent any
options {
skipDefaultCheckout(true)
}
stages {
stage('Checkout') {
steps {
checkout([
$class: 'GitSCM',
branches: scm.branches,
doGenerateSubmoduleConfigurations: scm.doGenerateSubmoduleConfigurations,
extensions: scm.extensions + [[$class: 'RelativeTargetDirectory', relativeTargetDir: 'reps/reponame']],
userRemoteConfigs: scm.userRemoteConfigs
])
}
}
}
}
In the context of Pipeline Multibranch, for each branch the SCM configuration is “injected” in the variable scm.
Build Step
The build step is big shell script. Jenkinsfiles support the
''' multi-line string so we take advantage of it.
Unfortunately though some of sed commands in the shell script
resulted in errors being thrown.
WorkflowScript: 35: unexpected char: '\'
It is possible to escape the '\' character but that becomes tedious when the script is also used in other contextes. So we prefered to rewrite it without any special character sequence.
Multi-configuration
Once you understand that multi-configuration means Matrix in Jenkins' world, you can find many examples.
The issue in many matrix tutorials is they skip over the basic use case of what happens to the generated files. It is important to realize that, even on a single host, the matrix items will be executed in a different WORKSPACE. As a result you need a way to bring the test result files to the master mode for post actions to find them.
There is a plethora of options to download, upload or otherwise copy file between workspaces. We finally stumbled upon stash and unstash as a working solution.
pipeline {
agent any
stages {
stage ("Setup Combinations") {
matrix {
agent any
axes {
axis {
name 'TOXENV'
values "py27-django1.11", "py36-django1.11", "py36-django2.2"
}
}
stages {
stage('Run') {
steps {
sh 'run.sh'
}
}
stage('Teardown') {
steps {
stash name: "${env.TOXENV}", includes: "**/results/*"
}
}
}
}
}
stage("Unstash outputs") {
steps {
unstash "py27-django1.11"
unstash "py36-django1.11"
unstash "py36-django2.2"
}
}
}
}
Publishing Reports
We are adding a post step to the pipeline so static and runtime
analyis reports are published in all cases, tests passing or failing.
post {
always {
recordIssues(tools: [esLint(pattern: '**/results/eslint.xml'), pyLint(pattern: '**/results/pylint.log')])
junit '**/results/client-test.log'
publishCoverage adapters: [coberturaAdapter(path: '**/results/coverage.xml', mergeToOneReport: true)], sourceFileResolver: sourceFiles('STORE_LAST_BUILD')
}
}
The good news is that with the previous post step, the result
files for all configurations are taken into account. There are no overrides
of one configuration results by another one. None-the-less, there are
adjustments to be made.
We already described the search-and-replace magic happening in coverage files.
Of notice here is the mergeToOneReport: true statement
used to merge coverage files from all configurations into a single
file before publishing.
When running a multi-configuration job, finding configurations that are failing is straightforward (first screenshot). With pipeline jobs, we have to rely on the way junit result files are parsed by the presentation plugin (second screenshot).
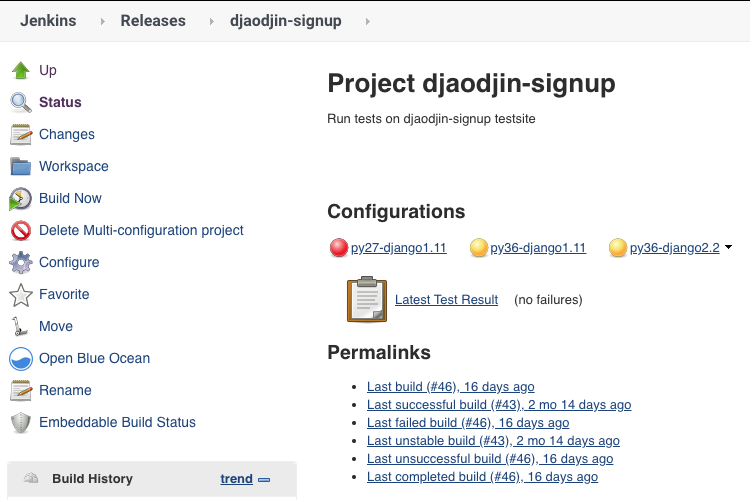
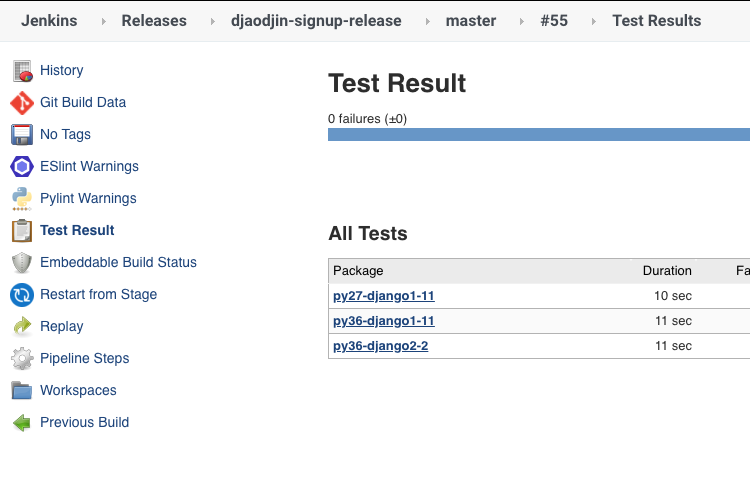
We do a search and replace in the junit file before it is processed such that
after processing package attributes match the desired
matrix variables.
Since JUnit result files are XML files designed for Java class files,
'.' serves as a separator, with the consequence that Jenkins
uses '.' for page separation. We thus need to ensure the
matrix variables do not themselves contain '.' characters.
Commenting on pull request
The goal is for the buildbot to indicate the status of running tests on the pull request. Between documentation on adding a comment and post section, we come up with the following pipeline snipset.
post {
success {
script {
if (env.CHANGE_ID) {
pullRequest.removeLabel('Fail')
pullRequest.addLabel('Pass')
}
}
}
failure {
script {
if (env.CHANGE_ID) {
pullRequest.removeLabel('Pass')
pullRequest.addLabel('Fail')
}
}
}
}
First build is not successful and raises the following exception:
groovy.lang.MissingPropertyException: No such property: pullRequest for class: groovy.lang.Binding
As it turns out we had installed the GitHub Pipeline for Blue Ocean plugin assuming it was the most recent GitHub Pipeline plugin. In order to use pullRequest we need to also install Pipeline: GitHub.
Second build we went further but stumbled up:
Error when executing failure post condition: org.eclipse.egit.github.core.client.RequestException: Must have admin rights to Repository. (403)
It might also be a clue of why, despite having a buildbot set as a member of the organization and a GitHub token with repo:status, we see the following error at the end of the log:
Could not update commit status, please check if your scan credentials belong to a member of the organization or a collaborator of the repository and repo:status scope is selected
Switching the buildbot from member to owner on GitHub seems to do the trick. That is just a lot of privileges for a buildbot though. Browsing through GitHub settings, we are hinted to rename Owners team into Admins team. We then add buildbot to it, and downgrade its role from owner to member again. Build still works!
More to read
You might also like to read Export Python Code Coverage from a Docker Container to Jenkins or Jenkins, Docker and Amazon EC2 Container Registry.
More technical posts are also available on the DjaoDjin blog, as well as business lessons we learned running a SaaS application hosting platform.
by Sebastien Mirolo on Wed, 15 Apr 2020
